はてなブックマークのコメントにおける流行語の調査
この記事はCAMPHOR- Advent Calendar 2017の24日目の記事です。
はじめに
前回の記事ではスクレイピングの練習として, はてなブックマークの人気エントリの一覧から情報を抽出してみました. 今回は, その続きとしてAPIを使いながら, エントリーに対するコメントを取得してみます. 「流行語の調査」という大げさなタイトルですが, 要するに 単語を数えてみたよ というだけの記事です.
APIによるコメントの取得
はてなブックマークエントリー情報取得APIを利用する事で, エントリーに対するコメントや, ブックマークをしたユーザIDなどを取得できます. /entry/json/ エンドポイントは関連エントリーに対する情報も返ってくるので, それが不要場合には
/entry/jsonlite/ を使えば関連エントリーを返さないのでレスポンスが高速になります. また, URLよってはブックマーク情報を公開していない物もあるため, 実装する際にはレスポンスの中身を確認する必要があります.
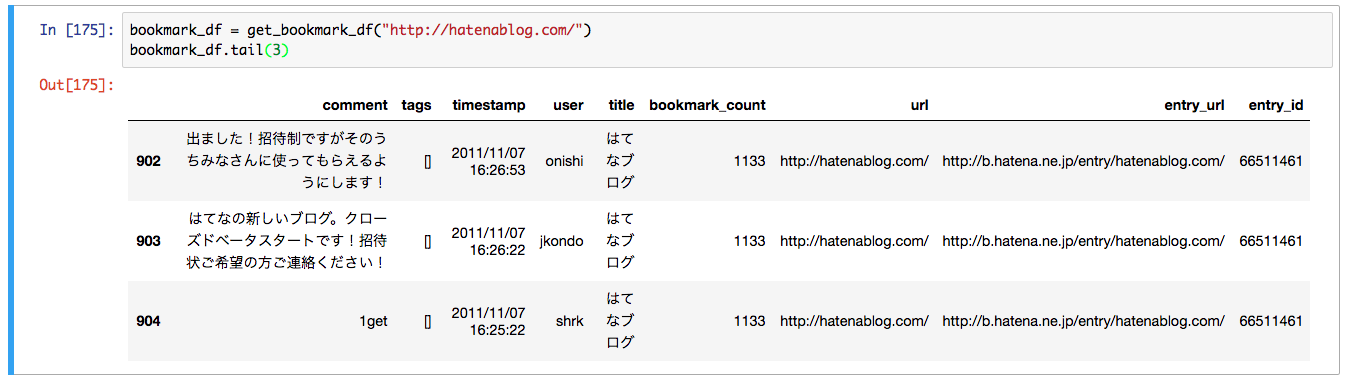
import urllib from pandas import DataFrame from pandas.io.json import json_normalize def get_bookmark_df(target_url): url = "http://b.hatena.ne.jp/entry/jsonlite/?" + urllib.parse.urlencode({"url": target_url}) res = requests.get(url).json() if res and ("bookmarks" in res.keys()): bookmark_df = DataFrame.from_dict(json_normalize(res["bookmarks"]), orient='columns') bookmark_df["title"] = res["title"] bookmark_df["bookmark_count"] = res["count"] bookmark_df["url"] = res["url"] bookmark_df["entry_url"] = res["entry_url"] bookmark_df["entry_id"] = res["eid"] return bookmark_df bookmark_df = get_bookmark_df("http://hatenablog.com/")
これを実行するとこんな感じになります. comment カラムにブックマークした際のコメントがある事が分かります.
(URLによってはタグ情報がないものもあるので注意して下さい.)
 gyazo.com
gyazo.com
流行語が知りたい
毎年この季節になると, 1年の流行語が発表されます.
www.oricon.co.jp
個人的には流行語というのは, 自分のいる環境や関心のあるトピックによって納得度が変化すると思います.
今年の「インスタ映え」という言葉は自分では全く使っていないし, 周りにもそのような言葉を使う人がいなかったので, 納得度が低いです.
そこで, 自分が毎日利用しているはてなブックマークでは, 他の人達がどのような言葉を使っていたのかを調べたくなりました.
どうやって調べるの?
(正しい流行語の定義が何かよく分かりませんが...)
今回は1年毎に, はてなブックマークのコメントで使われた単語を数えて行き, 以下の式で単語の流行度を計算します.

コメントを単語に分割する際の形態素解析にはMeCabを, 辞書にはmecab-ipadic-neologdを使用します.
流行度の計算に使用するコメントは, はてなブックマークの「世の中」のカテゴリにおける, 1日ごとの人気エントリ一覧に対してのコメントです.
このコメントを2014年~2017年について各365日分集めました. (2017年分は12月19日までのデータを使用しています.)
コメントの中には, 2016年のエントリに対して2017年にコメントされた物もありますが, その場合には流行度の計算から除外しています.
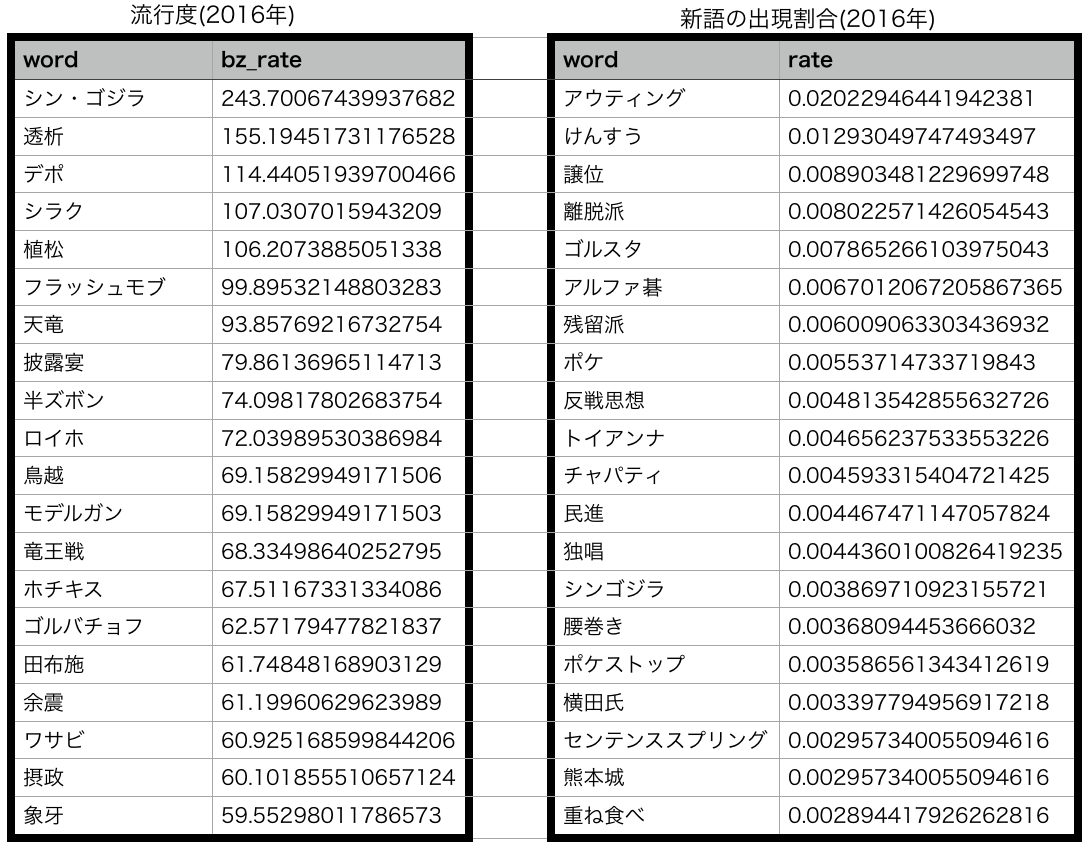
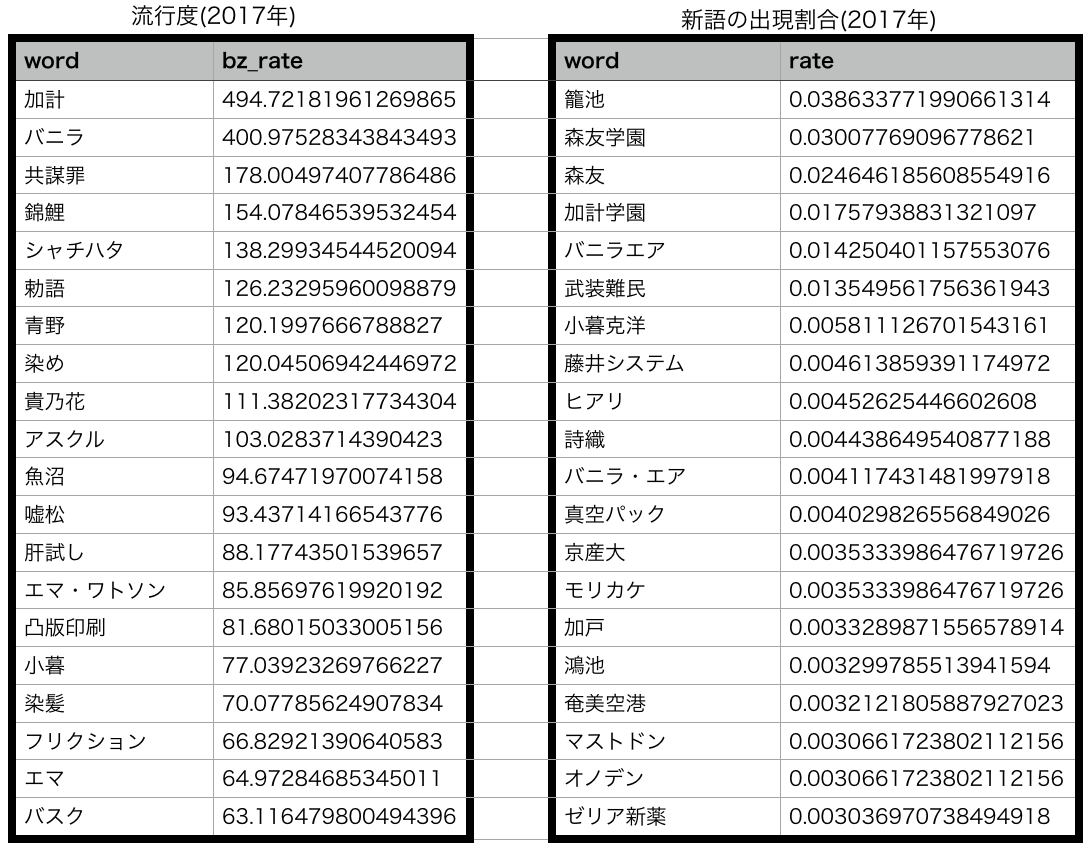
調査結果
コメントの総数は 7,307,039 となりました.
流行度の上位20語と, 前年の単語には無かった新語達についてはその年での出現割合の上位20語を出してみました.

まとめ
スクレイピングとAPIを使って, はてなブックマークのコメントから単語を数えてみました.
データを集めるのに苦労しましたが, 流行度の上位20語については正直微妙な結果になってしまった感があります...
明日は shiba6v が担当です. お楽しみに.
はてなブックマークの人気エントリーの情報を抽出する
この記事は CAMPHOR- Advent Calendar 2017 9日目の記事です.
こんにちは, ohmurakenです.
スクレイピングの練習も兼ねて, はてなブックマークの人気エントリーの情報を抽出してみたよという記事です.
人気エントリー
はてなブックマークでは以下のようなURLで日にち毎の人気エントリーがまとめられています.
http://b.hatena.ne.jp/hotentry/{category}/{YYYYMMDD}
例えばテクノロジーカテゴリに関する, 2017年12月5日の人気エントリーの一覧ページのURLは以下のように定義されています.
http://b.hatena.ne.jp/hotentry/it/20171205
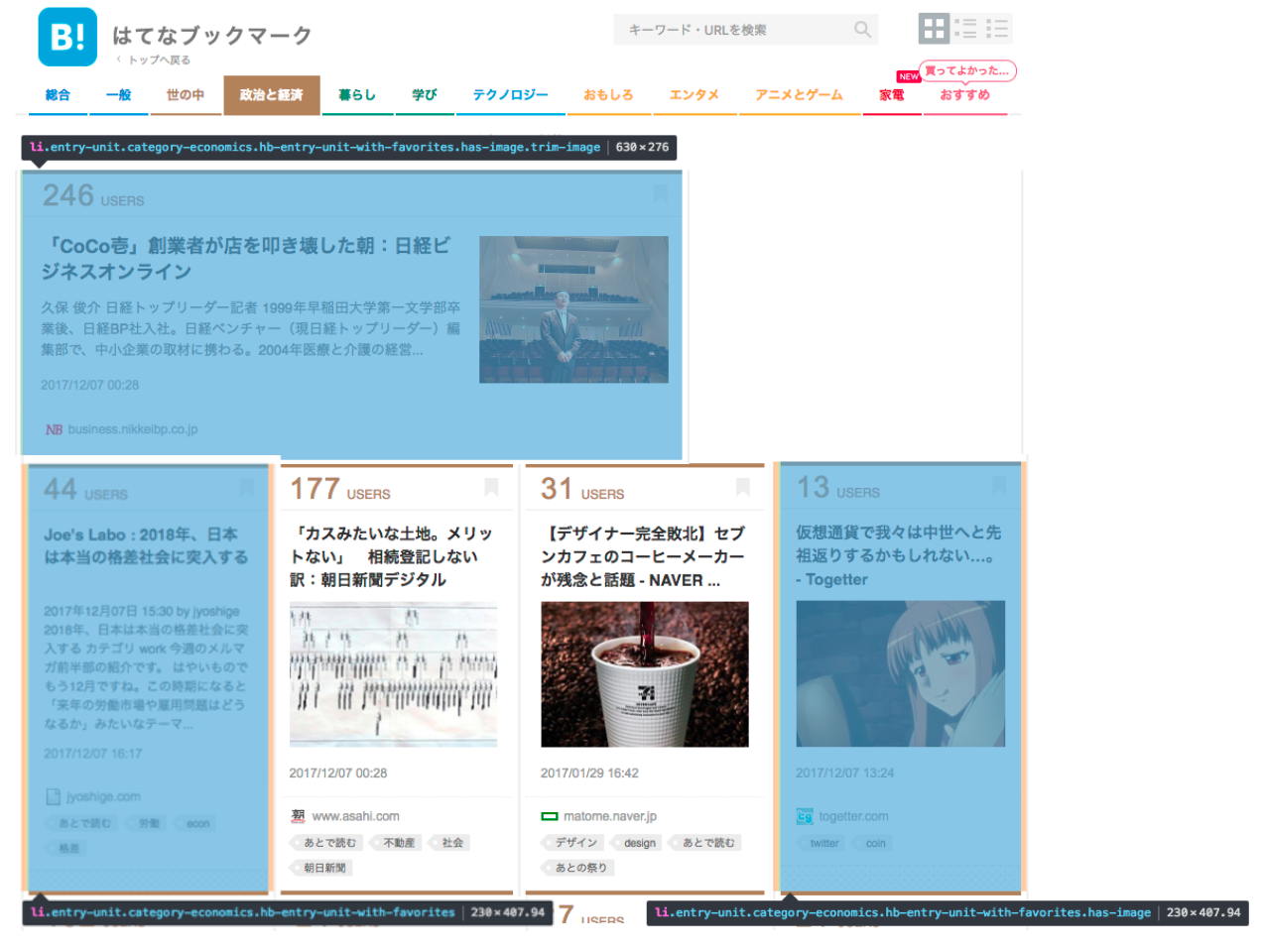
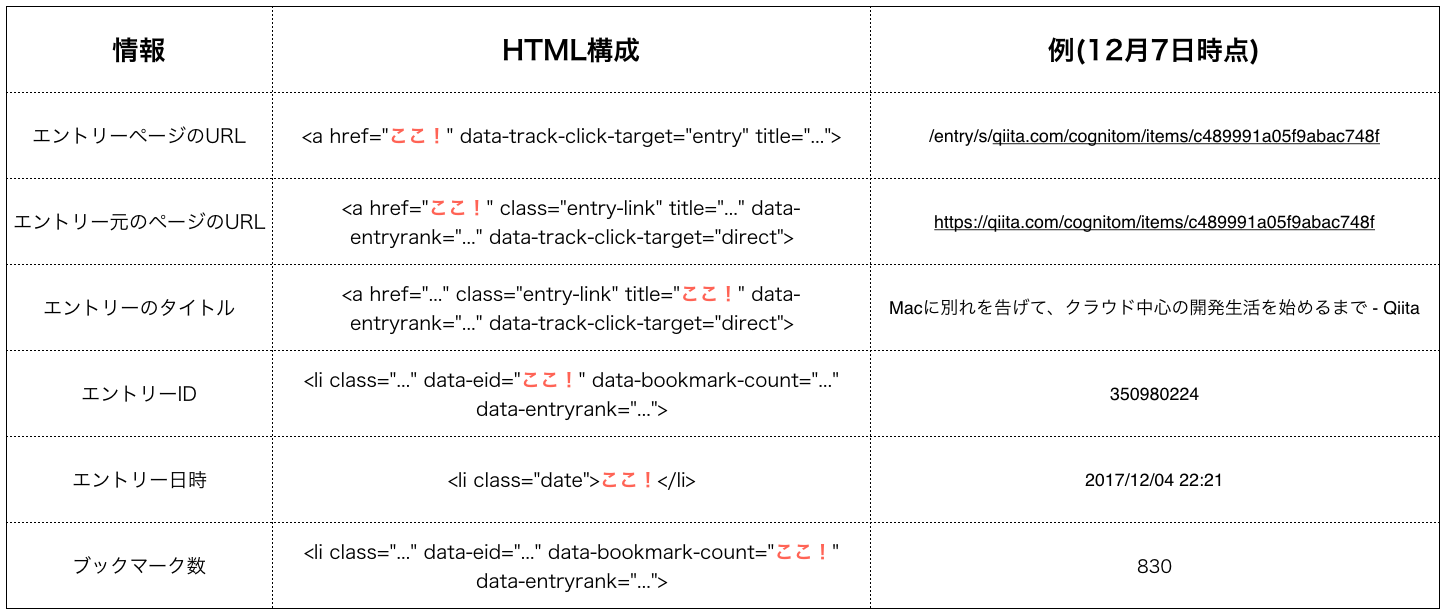
一覧ページのHTML構成
人気エントリーのページは1つのタイル内にエントリーの情報が埋め込まれています. それぞれのタイルはHTMLのliタグで区切られており, 複数のclass名が用いられています.
| liタグのclass名 | タイル内のコンテンツ |
|---|---|
| entry-unit category-{category} hb-entry-unit-with-favorites | テキスト |
| entry-unit category-{category} hb-entry-unit-with-favorites has-image | 画像 |
| entry-unit category-{category} hb-entry-unit-with-favorites has-image trim-image | トリミング画像 |
Chromeのデベロッパーツールで確認するとよくわかります.
個々のエントリー情報の抽出
次にタイルの中から情報を抽出してみます.
タイル内では各情報が以下のようにHTMLで記述されています.
Pythonによる実装
Pythonで実装するならBeautifulSoupというライブラリを使うと簡単にHTMLを解析する事ができ, 一覧ページのHTMLをBeautifulSoupにParseさせると, タグ名やクラス名を指定する事で要素や値を抽出する事ができます. また, pandas.DataFrameと組み合わせるとシュッと表形式で格納できます.
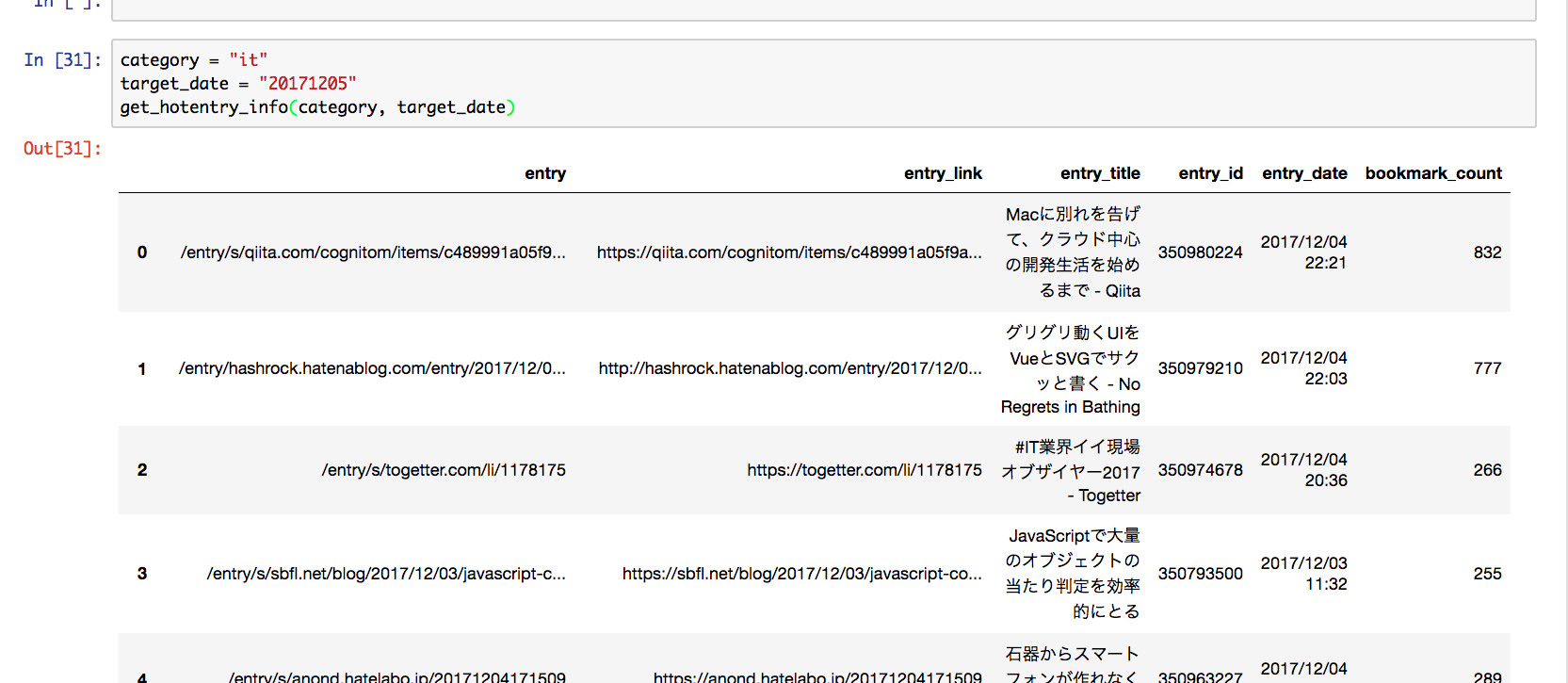
import requests from collections import OrderedDict from bs4 import BeautifulSoup as bs from pandas import DataFrame def get_hotentry_info(category, target_date): url = "http://b.hatena.ne.jp/hotentry/{}/{}".format(category, target_date) res = requests.get(url) soup = bs(res.text, 'html.parser') check_list = [ "entry-unit category-{} hb-entry-unit-with-favorites has-image".format(category), "entry-unit category-{} hb-entry-unit-with-favorites".format(category), "entry-unit category-{} hb-entry-unit-with-favorites has-image trim-image".format(category) ] # HTMLからタイルのみを抽出する tiles = soup.find_all("li", {"class": check_list}) # 格納する辞書とDataFrameを用意 entry_info = OrderedDict({}) hotentry_df = DataFrame() # 個々のタイルからエントリー情報を抽出する for tile in tiles: entry_info["entry"] = tile.find("a", {"data-track-click-target": "entry"})["href"] entry_info["entry_link"] = tile.find("a", {"class": "entry-link"})["href"] entry_info["entry_title"] = tile.find("a", {"class": "entry-link"})["title"] entry_info["entry_id"] = tile.attrs["data-eid"] entry_info["entry_date"] = tile.find("li", {"class": "date"}).string entry_info["bookmark_count"] = tile.attrs["data-bookmark-count"] hotentry_df = hotentry_df.append([entry_info], ignore_index=True) return hotentry_df if __name__ == "__main__": category = "it" target_date = "20171205" print(get_hotentry_info(category, target_date))
実行すると以下のような結果が得られます. (実行結果は12月7日時点のものです.)
まとめ
はてなブックマークの人気エントリーから情報を抽出する方法をまとめてみました. エントリーに対するコメントやスターについては, はてなブックマーク REST APIやはてなスター取得 APIを使用するとサクッと取得できます.
CAMPHOR- Advent Calendar 2017 明日の担当は @kasajei の『面白い本の選び方 〜ハズレ本は読み捨て、タイトルに騙されずに翻訳本を買え!』です. お楽しみに!
サッカーのデータを分析しよう
こんにちは, ohmurakenです. 好きなサッカーチームはリバプールFCです.
この記事は, CAMPHOR- Advent Callendar 2016の5日目の記事です.
サッカーに関するデータの収集と分析について書きたいと思います.
目次
- やろうと思った理由
- データの収集
- 簡単な分析
- まとめ
やろうと思った理由
今年, 初めてPyCon JPに参加しました. 機械学習や分析に関するセッションを観ていましたが, ビッグデータとPythonではじめる野球の統計分析というセッションが興味深いものでした. このセッションは, 野球(特に大リーグ)に関するデータを収集し, 分析する事で選手の特徴や変化を調べるという内容です(セッションの動画). このセッションを観た時, サッカーでも同様の事ができないかと思いました. 強いチームの特徴などを数値的に分析できると思ったからです.
データの収集
GitHubにサッカーのデータを集めているfootball.dbというOrganizationがありました. football.dbのリポジトリの中で特にStarが多いfootball.jsonには次のようなデータが定義されています.
{
"name": "English Premier League 2015/16",
"rounds": [
{
"name": "Matchday 1",
"matches": [
{
"date": "2015-08-08",
"team1": {
"key": "manutd",
"name": "Manchester United",
"code": "MUN"
},
"team2": {
"key": "tottenham",
"name": "Tottenham Hotspur",
"code": "TOT"
},
"score1": 1,
"score2": 0
},
試合の日時と,ホームアウェイのチームとスコアが素性としてありますが, もう少し情報が欲しいなと思いました.
結果的に, Football-Data.co.ukというサイトに良さげなデータがありました. Notesにもあるように, 1つの試合に対して65の素性があります. (半分以上はオッズに関する情報ですが...)
下のように, シュートやコーナーキックなど前後半に分けて比較的細かく情報が定義されています.

簡単な分析
Football-Data.co.ukのデータを使って, 簡単な分析をしてみます.
日本代表の試合後のインタビューで選手が「決定力が不足が原因で〜」という内容を話している場面を良く観ます.
新聞やニュースサイトでも決定力については度々指摘されており, チームの強さと決定力について分析する必要があると思います.
 そこで, 「決定力の高いチームは強い(つまり勝ち点が多い)」という仮説の基で, プレミアリーグ(15~16)での決定力と勝ち点について調べてみます.
以下では, 決定力を定量的に考えるために決定力=ゴール数÷シュート数とします.
そこで, 「決定力の高いチームは強い(つまり勝ち点が多い)」という仮説の基で, プレミアリーグ(15~16)での決定力と勝ち点について調べてみます.
以下では, 決定力を定量的に考えるために決定力=ゴール数÷シュート数とします.
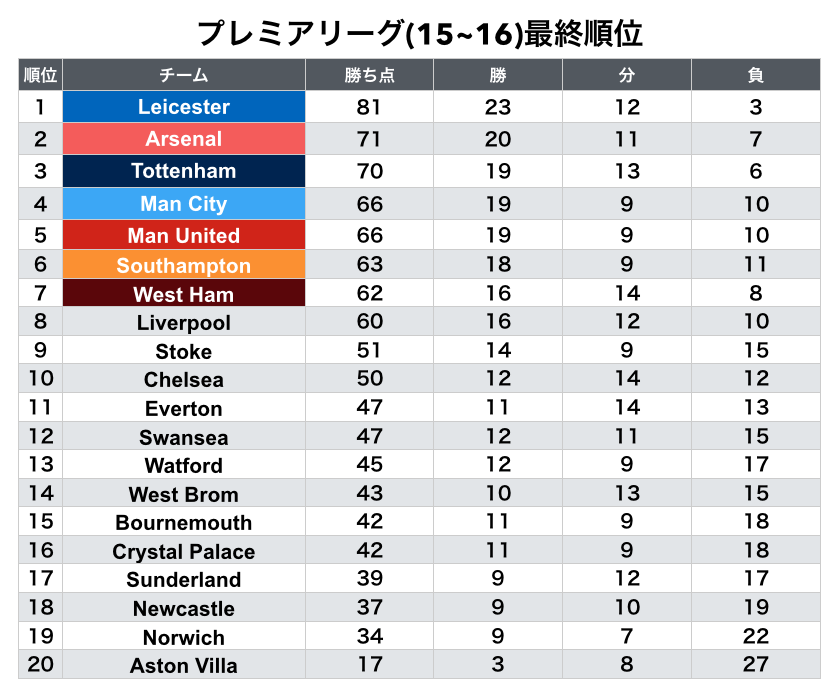
まず最終順位を観てみましょう.
プレミアリーグ(15-16)ではレスターが優勝して世界中が驚きました. それ以外にも, トッテナムの若手達の攻撃力も魅力的でした. 特にハリー・ケインはテクニックだけでなく, シュートも打てる凄い選手です.
 gyazo.com
gyazo.com
先程, 決定力=ゴール数÷シュート数としたので, チームの得点数とシュート数を観てみましょう.
優勝したレスターとエバートンの決定力の高さが目立ちます. レスターは総合力では上位チームに劣るため, カウンターを活用していました. レスターのエースであるバーディーの速さもあり, 少ないチャンスで得点する事ができていました.
一方でトッテナムとアーセナルは, シュート数に比べてゴール数が少なく, 決定力では中位に位置しています. トッテナムのシュート数661は2位のチームと大きく差をつけており, トッテナムの攻めの姿勢の強さを示しています. 個人的には「赤い悪魔」の愛称で知られるマンチェスターUTDのシュート数がリーグ内でも下位なので寂しくなりました.
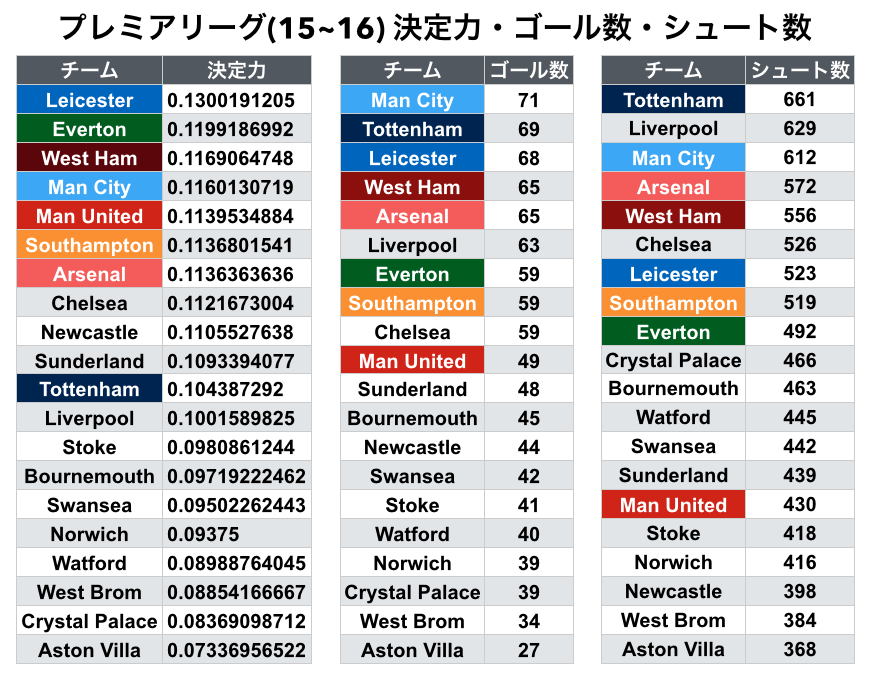 gyazo.com
gyazo.com
ヨーロッパのリーグは選手と観客がとても近く, ホーム試合かアウェイ試合かどうかで大きく影響があると考えられます.
そこで, ホームとアウェイでの決定力の変化が気になるので, 調べてみます.
ニューカッスルUTDとサウサンプトンとはホームで決定力がとて高いですが, アウェイでは一変して定力が低くなります. 一方でアーセナルはアウェイになると決定力が上がります.
レスターは流石優勝という感じで, ホームでもアウェイでも, 高い決定力を示しています.
 gyazo.com
gyazo.com
勝ち点と決定力の相関を調べます.
(当然ですが)相関係数が高いと, 「決定力が高い程, 勝ち点が多い(決定力が低い程, 勝ち点が少ない)」事を示します. 今回は, 勝ち点と前述の決定力の相関係数(ピアソン)を調べます.
ピアソンの相関係数は以下の式で表せます.

全ての試合に対して, 各チームの勝ち点と決定力の相関係数は0.73となりました.
やはり決定力が高いチームほど強いという仮説は間違っていなかったようです. p値も5%より低い値を示しています.
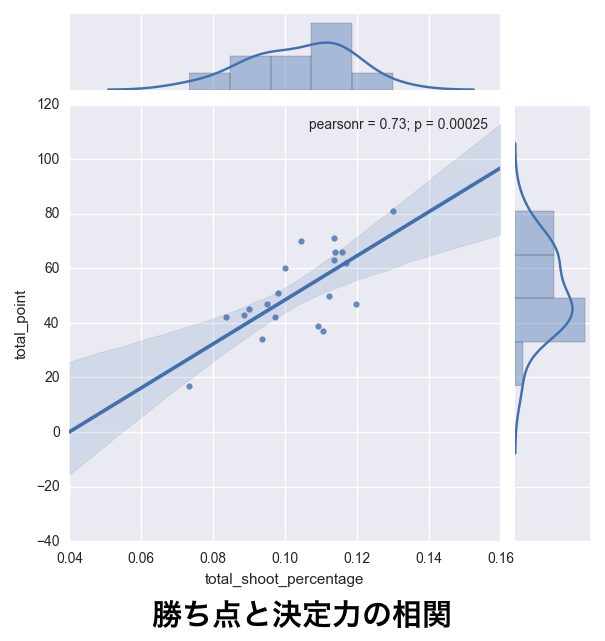 gyazo.com
gyazo.com
先ほど, ホームとアウェイで決定力に違いがあったので, ホームとアウェイでの相関も気になります.
ホームでの勝ち点と決定力の相関係数は0.51となりました. ホームで決定力が高いのは当然であるため, ある程度の相関しか示していません.
 gyazo.com
gyazo.com
アウェイでの勝ち点と決定力の相関係数は0.67となりました. アウェイでの決定力の方が, ホームよりも相関が強くなる事が解りました.
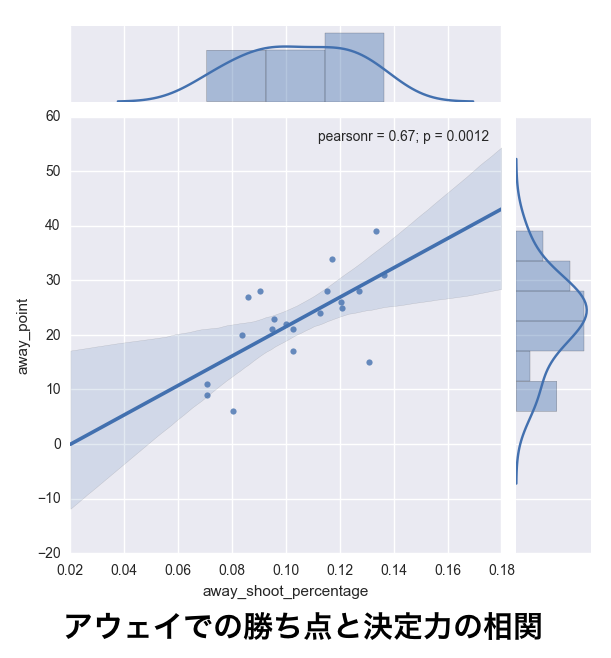 gyazo.com
gyazo.com
ここで気になるのが, 過去のシーズンでの相関です.
15~16はホーム試合での勝ち点と決定力の相関が低いシーズンでした. 過去の推移を観ると, ホームとアウェイでの相関係数は同じ様な値を取り, 2~3年に1度の機会でホーム(もしくはアウェイ)の相関が乱れる様です.
 gyazo.com
gyazo.com
まとめ
この記事では, サッカーのデータ分析に使えそうなデータを探し, 決定力の高いチームは強いという仮説のもとで, 決定力(=ゴール数÷シュート数)と勝ち点の相関を調べました.
結果的に, 以下の事が解りました.
- 総合力に劣るチームは決定力が高く, 少ないシュートでゴールを量産していた.
- ホームとアウェイで決定力が大きく変化するチームがいた.
- 決定力と勝ち点には強い相関があった.
- 15~16シーズンでは, 特にホームでの決定力よりも, アウェイでの決定力の方が相関が強かった.
「そりゃあ, そうだろ」という感じですね.
今後は選手を多次元で数値化し, チームの順位を予測するようなモデルを作ってみたいです.
明日のCAMPHOR- Advent Calendarはtomoyat1の『ZFS SnapshotをGCPのColdline Storageに上げてみた』です.
参考
www.slideshare.net
www.slideshare.net