はてなブックマークの人気エントリーの情報を抽出する
この記事は CAMPHOR- Advent Calendar 2017 9日目の記事です.
こんにちは, ohmurakenです.
スクレイピングの練習も兼ねて, はてなブックマークの人気エントリーの情報を抽出してみたよという記事です.
人気エントリー
はてなブックマークでは以下のようなURLで日にち毎の人気エントリーがまとめられています.
http://b.hatena.ne.jp/hotentry/{category}/{YYYYMMDD}
例えばテクノロジーカテゴリに関する, 2017年12月5日の人気エントリーの一覧ページのURLは以下のように定義されています.
http://b.hatena.ne.jp/hotentry/it/20171205
一覧ページのHTML構成
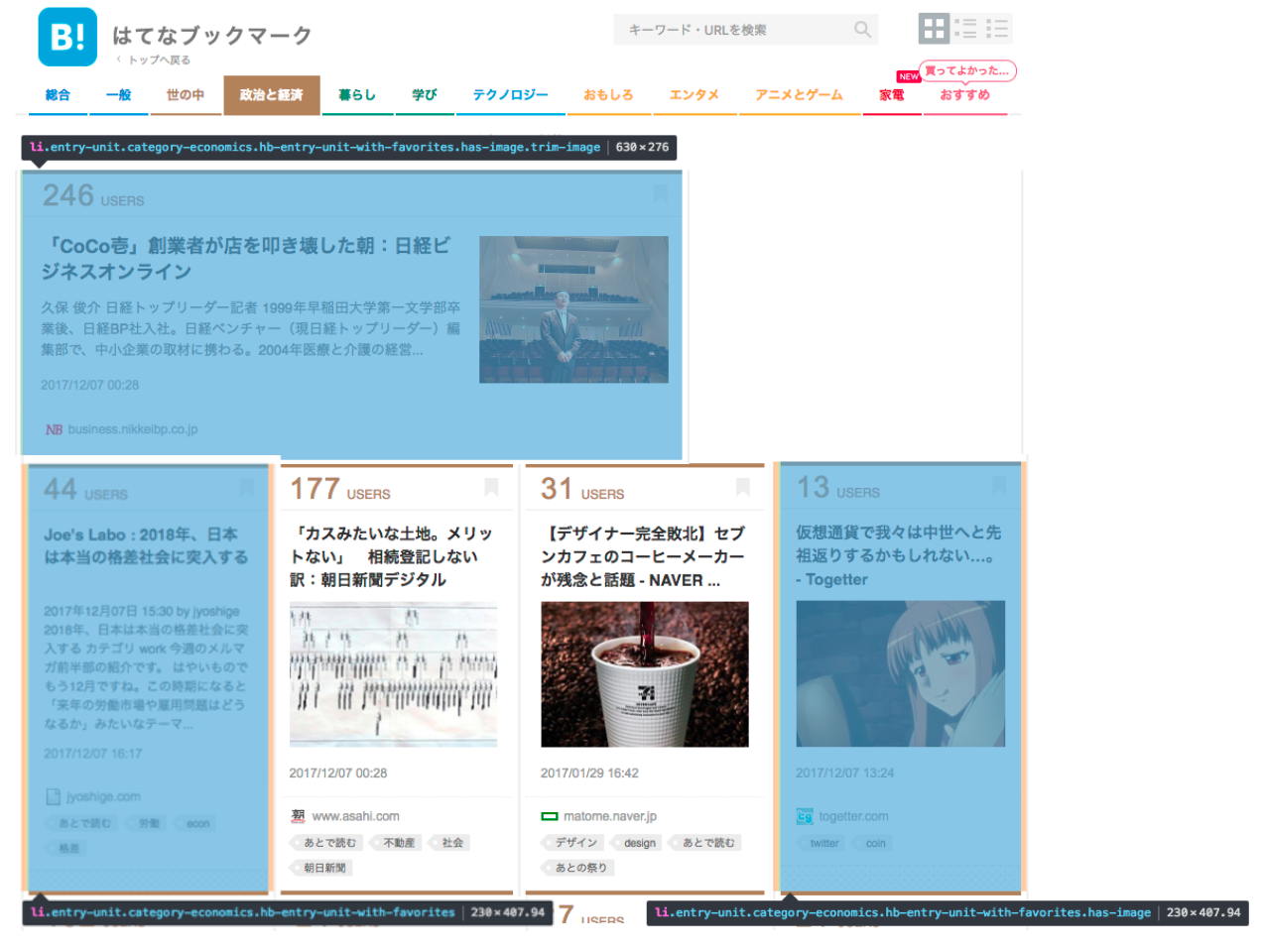
人気エントリーのページは1つのタイル内にエントリーの情報が埋め込まれています. それぞれのタイルはHTMLのliタグで区切られており, 複数のclass名が用いられています.
| liタグのclass名 | タイル内のコンテンツ |
|---|---|
| entry-unit category-{category} hb-entry-unit-with-favorites | テキスト |
| entry-unit category-{category} hb-entry-unit-with-favorites has-image | 画像 |
| entry-unit category-{category} hb-entry-unit-with-favorites has-image trim-image | トリミング画像 |
Chromeのデベロッパーツールで確認するとよくわかります.
個々のエントリー情報の抽出
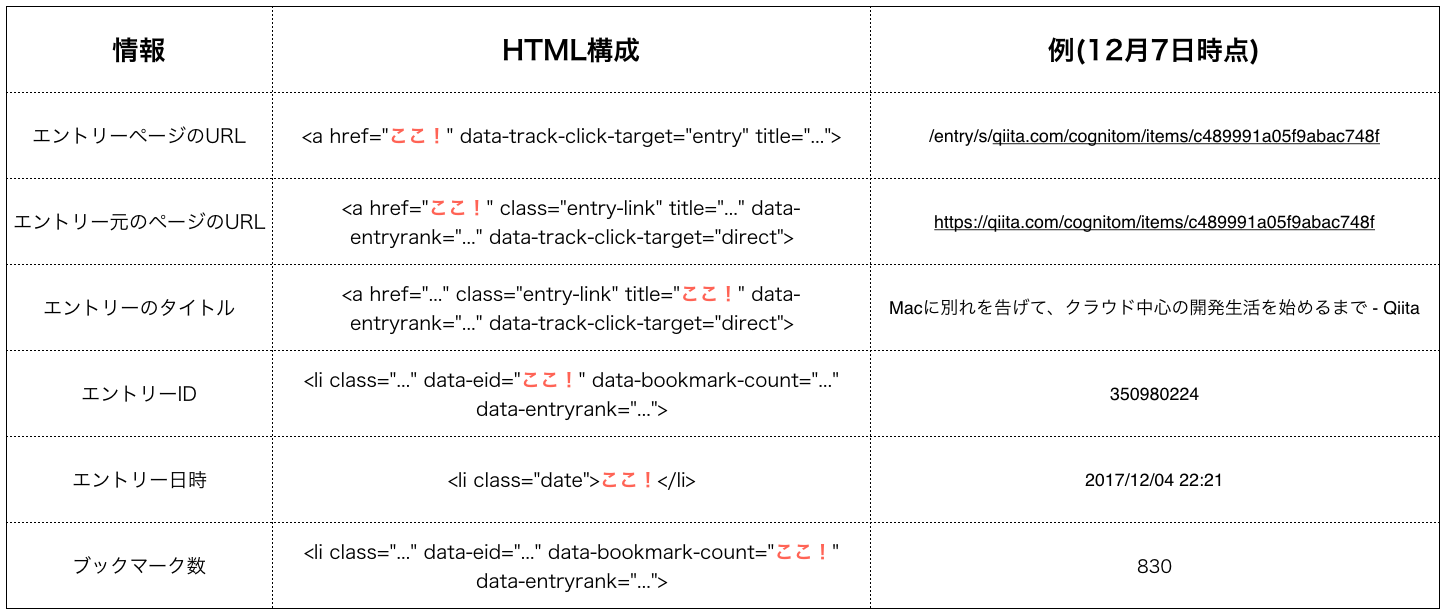
次にタイルの中から情報を抽出してみます.
タイル内では各情報が以下のようにHTMLで記述されています.
Pythonによる実装
Pythonで実装するならBeautifulSoupというライブラリを使うと簡単にHTMLを解析する事ができ, 一覧ページのHTMLをBeautifulSoupにParseさせると, タグ名やクラス名を指定する事で要素や値を抽出する事ができます. また, pandas.DataFrameと組み合わせるとシュッと表形式で格納できます.
import requests from collections import OrderedDict from bs4 import BeautifulSoup as bs from pandas import DataFrame def get_hotentry_info(category, target_date): url = "http://b.hatena.ne.jp/hotentry/{}/{}".format(category, target_date) res = requests.get(url) soup = bs(res.text, 'html.parser') check_list = [ "entry-unit category-{} hb-entry-unit-with-favorites has-image".format(category), "entry-unit category-{} hb-entry-unit-with-favorites".format(category), "entry-unit category-{} hb-entry-unit-with-favorites has-image trim-image".format(category) ] # HTMLからタイルのみを抽出する tiles = soup.find_all("li", {"class": check_list}) # 格納する辞書とDataFrameを用意 entry_info = OrderedDict({}) hotentry_df = DataFrame() # 個々のタイルからエントリー情報を抽出する for tile in tiles: entry_info["entry"] = tile.find("a", {"data-track-click-target": "entry"})["href"] entry_info["entry_link"] = tile.find("a", {"class": "entry-link"})["href"] entry_info["entry_title"] = tile.find("a", {"class": "entry-link"})["title"] entry_info["entry_id"] = tile.attrs["data-eid"] entry_info["entry_date"] = tile.find("li", {"class": "date"}).string entry_info["bookmark_count"] = tile.attrs["data-bookmark-count"] hotentry_df = hotentry_df.append([entry_info], ignore_index=True) return hotentry_df if __name__ == "__main__": category = "it" target_date = "20171205" print(get_hotentry_info(category, target_date))
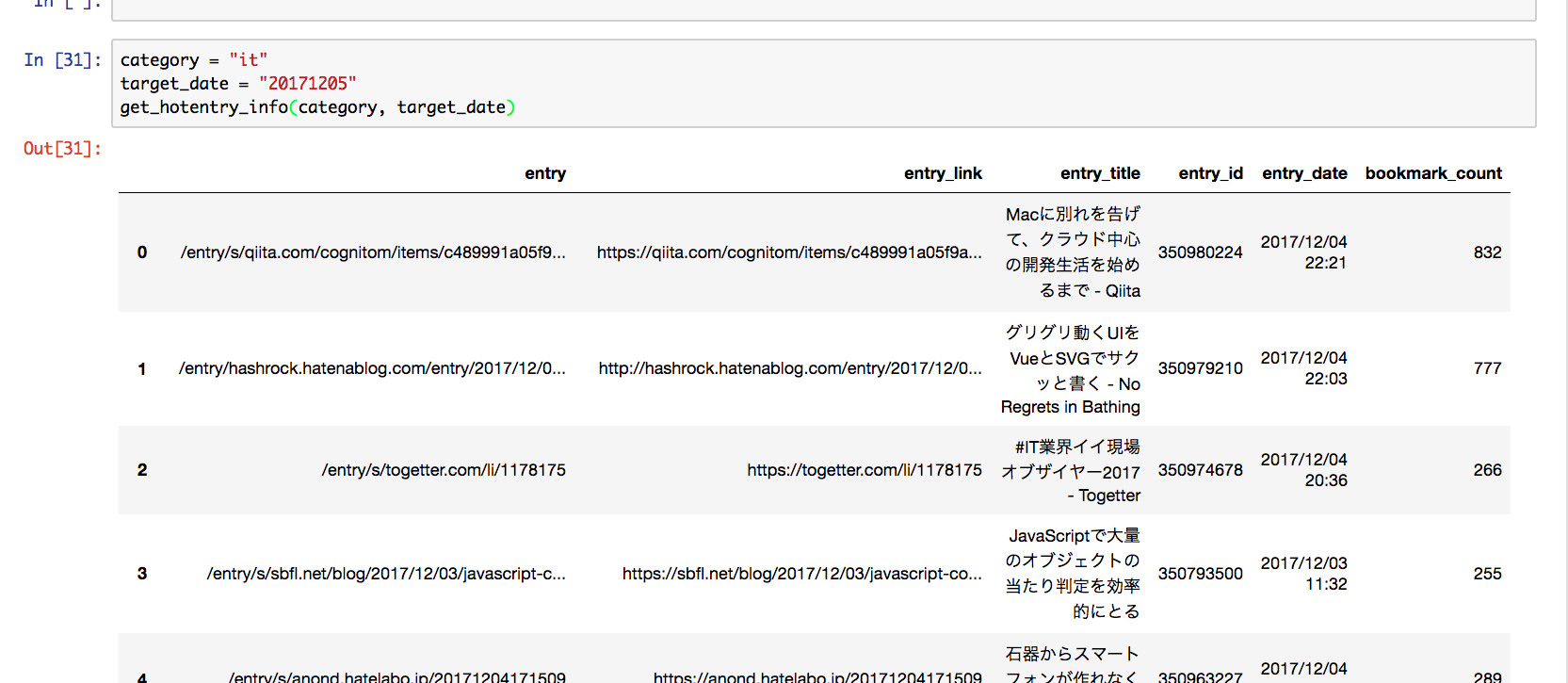
実行すると以下のような結果が得られます. (実行結果は12月7日時点のものです.)
まとめ
はてなブックマークの人気エントリーから情報を抽出する方法をまとめてみました. エントリーに対するコメントやスターについては, はてなブックマーク REST APIやはてなスター取得 APIを使用するとサクッと取得できます.
CAMPHOR- Advent Calendar 2017 明日の担当は @kasajei の『面白い本の選び方 〜ハズレ本は読み捨て、タイトルに騙されずに翻訳本を買え!』です. お楽しみに!